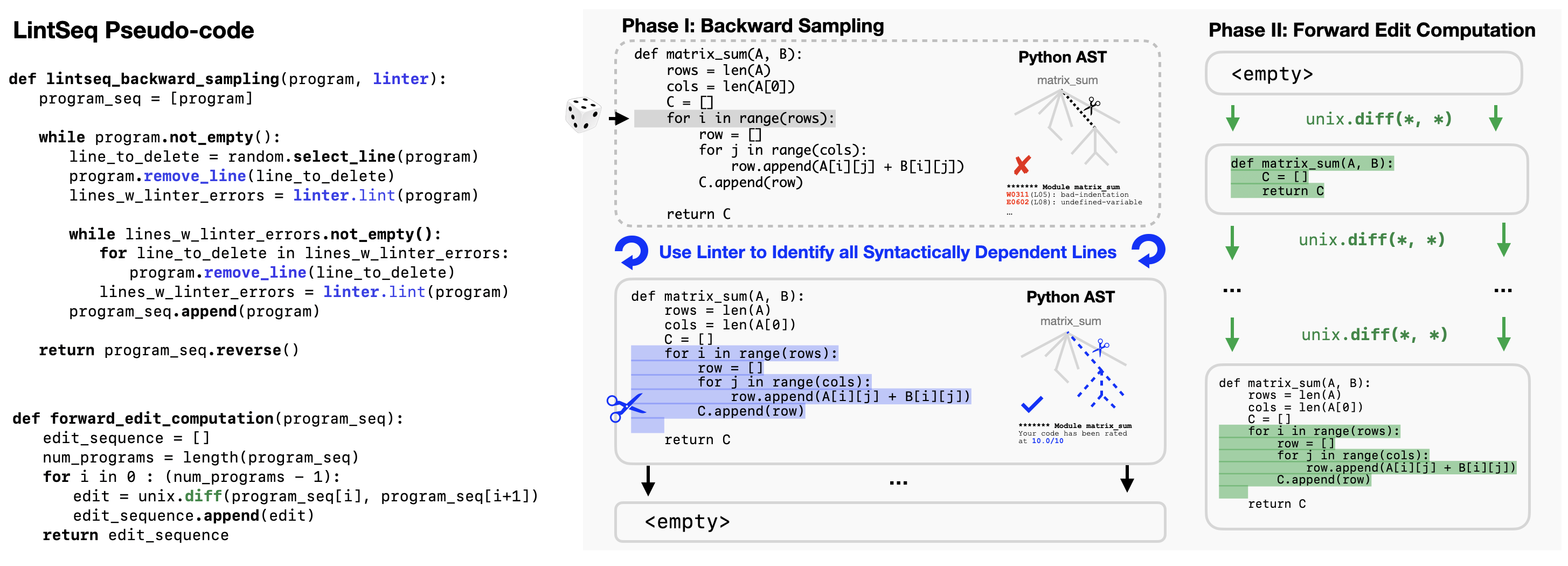
At each iteration, the LintSeq algorithm samples an edit chunk from a program by: randomly selecting a line of code to delete; identifying the minimal set of lines that are dependent on this line with a code linter; and finally, removing the line and its dependents. These steps are repeated until all lines of code have been removed. LintSeq then processes the reversed sequence of program states with Unix-diff to express it as a sequence of edits.
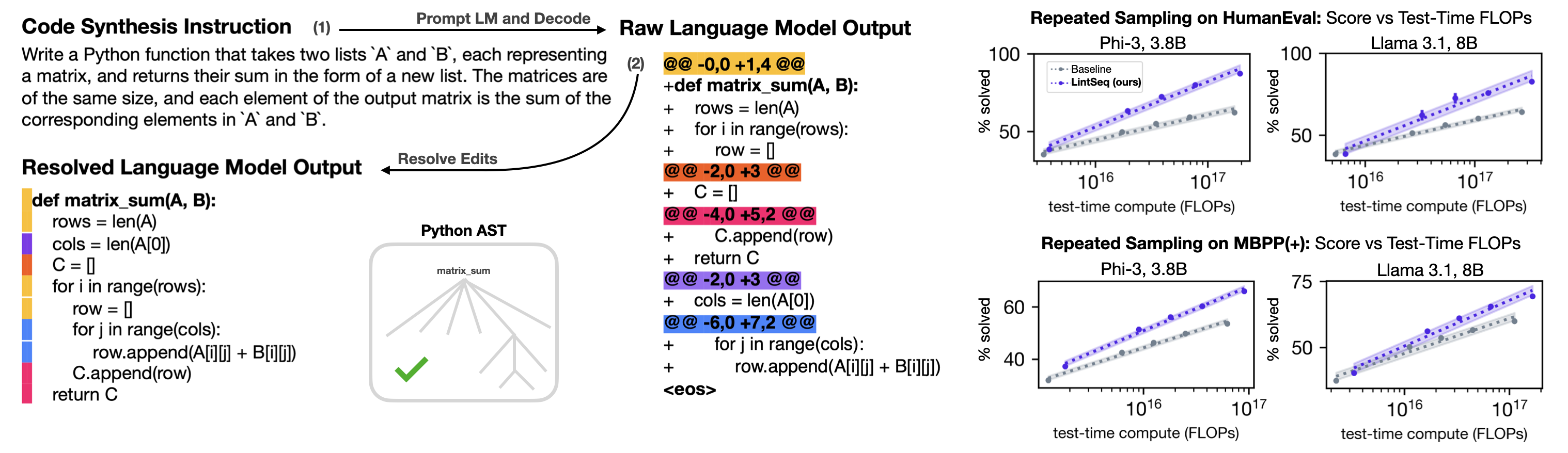
Intuitively, LintSeq decomposes source code across semantically/syntactically interdependent edit chunks. A synthetic Python edit output by LintSeq might contain: the full body of a "for" loop, a declaration of a variable (e.g. "a = 10") and all subsequent lines of code referencing this variable, or an entire function definition. By design, each LintSeq edit also satisfies a "linter-correctness" invariant, i.e. applying it to previously written code does not introduce new linter errors.
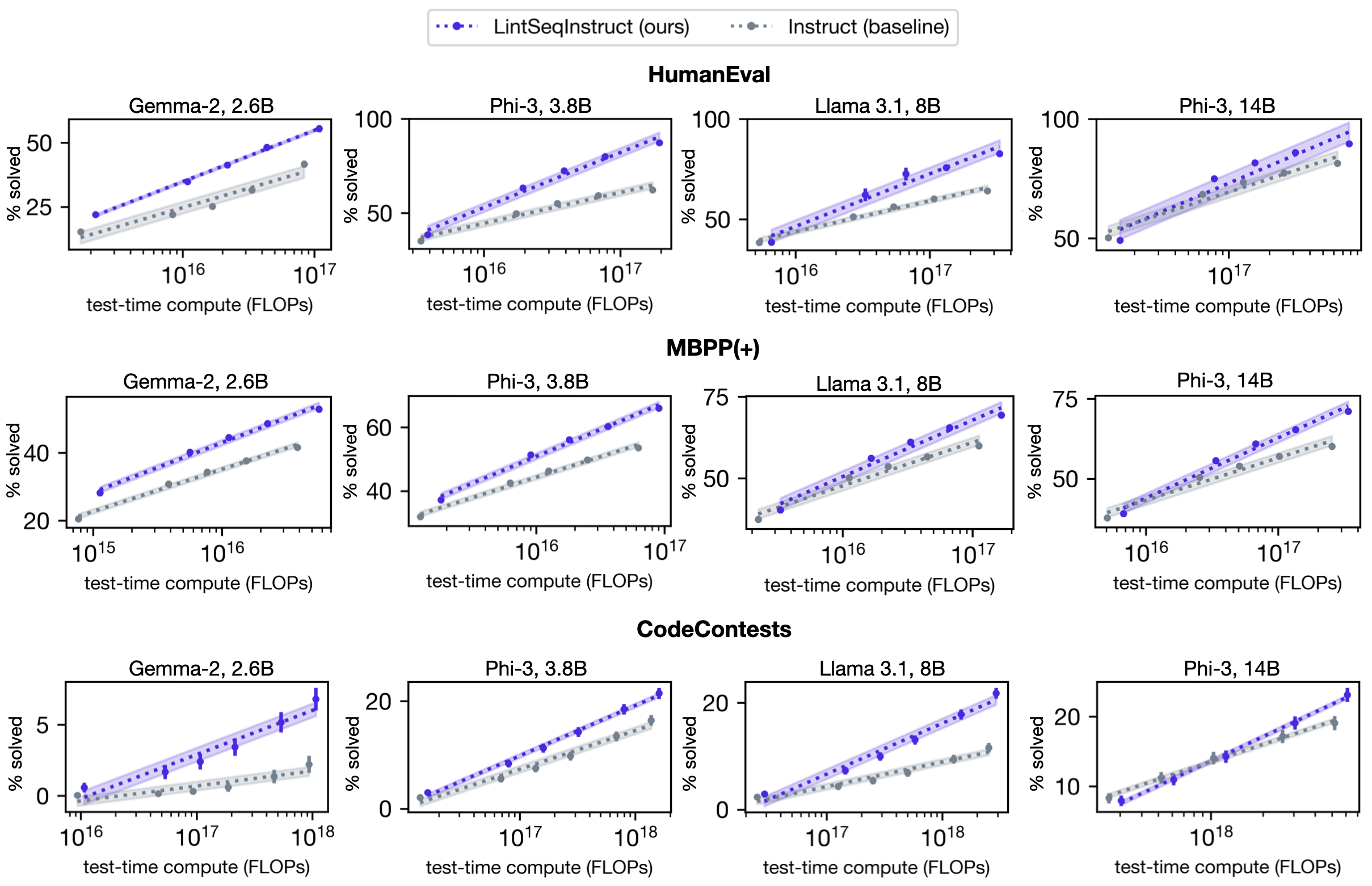
By adding edits that reflect programming language abstractions to instruction data with LintSeq, we train language models to synthesize programs one ("linted") edit at a time. This results in substantial improvements to the overall diversity of model-generated code, compared to training on a dataset of equivalent "single-shot" instruction data for code synthesis. The improved diversity of sampled programs means that pass@k performance increases faster as a function of test-time FLOPs, allowing for a better trade-off between the two. We demonstrate this effect on four different language models.
In the figure below, we report the best performance of models SFT-ed on edit sequence pre-processed vs standard instruction data after sweeping over sampling temperature, top-p, and min-p. We then plot benchmark score (pass@k) as a function of the total cost of repeated sampling from each model in FLOPs. Shading shows standard error in linear fit.
@misc{piterbarg2024editseq,
title={Training Language Models on Synthetic Edit Sequences Improves Code Synthesis},
author={Ulyana Piterbarg and Lerrel Pinto and Rob Fergus},
year={2024},
eprint={2410.02749},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
}